文/羅正漢 | 2025-04-18發表
隨著LLM(大型語言模型)在這兩年應用起飛,新技術也帶來新風險,過去經常發布10大資安風險的非營利組織OWASP,也針對新興的LLM應用程式公開排名,自2023年8月開始,發布「OWASP Top 10 for LLM Applications」1.0版,到2024年11月新公布2025年版,幫助開發者與安全專業人員對LLM風險的理解,以更全面的方式了解風險與攻擊面,並設法做到防護。
由於LLM正持續高速發展,大家對其危險性可能還處於一知半解的狀態,因此,我們決定以簡潔易懂的方式解釋,針對十項不同的風險,逐一說明。
特別的是,我們還搭配簡單圖示與文字說明,幫助讀者更輕鬆地理解這些複雜的概念。
OWASP十大LLM應用程式風險
LLM01:2025 提示詞注入(Prompt Injection)
LLM02:2025 敏感資訊揭露(Sensitive Information Disclosure)
LLM03:2025 供應鏈風險(Supply Chain)
LLM04:2025 資料與模型投毒(Data and Model Poisoning)
LLM05:2025 不當輸出處理(Improper Output Handling)
LLM06:2025 過度代理授權(Excessive Agency)
LLM07:2025 系統提示詞洩露(System Prompt Leakage)
LLM08:2025 向量與嵌入弱點(Vector and Embedding Weaknesses)
LLM09:2025 錯誤資訊(Misinformation)
LLM10:2025 無限資源耗盡(Unbounded Consumption)
風險1 提示詞注入(Prompt Injection)
使用者輸入的提示詞(Prompts)往往意外改變LLM的行為或輸出方式,而且,只要是模型能解析的內容,不需要是人類可讀的內容,同樣可能影響其運作。因此,攻擊者將可透過精心設計的提示詞輸入,讓LLM執行違反規定的操作。此項也常被稱為提示注入。
特別的是,在LLM安全中的「提示注入」與「越獄攻擊(Jailbreaking)」,兩者經常被交替使用,但彼此之間稍有差異,前者是透過特定輸入操控模型回應,後者是提示注入的一種形式,可使模型完全忽略安全規則。
具體而言,其攻擊情境相當多元,包括:直接注入攻擊、間接注入攻擊、惡意影響模型輸出、程式碼注入攻擊、負載拆分攻擊、多模態注入攻擊、對抗性後綴攻擊、多語言/混淆攻擊。
風險2 敏感資訊揭露(Sensitive Information Disclosure)
LLM的答覆可能意外洩漏了機敏資料,如個人資訊、財務記錄、健康資料、商業機密或安全憑證,甚至是專有的訓練方法或原始碼。因此,攻擊者可利用這個弱點作為其他攻擊的切入點。
洩漏可能發生在模型回應時,或是使用者也有無意間輸入敏感資訊,導致未授權存取、隱私侵犯或智慧財產外洩。雖然有3種常見方法可降低風險:資料過濾與清理、明確的使用條款,以及限制系統提示詞,但仍需注意,因為攻擊者可能透過提示注入繞過安全機制,洩漏不應公開的敏感資訊。
風險3 供應鏈風險(Supply Chain)
當LLM供應鏈存在多種漏洞,可能影響訓練資料、模型完整性與部署平臺,導致偏差輸出、資安漏洞或系統故障。攻擊者有可能會鎖定易受攻擊的組件或服務下手。
例如,可能發生外部資源遭到竄改(Tampering)的情形,或是投毒攻擊(Poisoning Attack),還有因為LLM訓練高度依賴第三方模型,再加上開放式LLM的出現,以及新興的微調技術(如LoRA、PEFT),這些都增加了供應鏈風險,並且對Hugging Face 等平臺造成更多影響。
不僅如此,還有隨著邊緣運算發展下的On-Device LLMs 興起,也同樣是擴大了攻擊面與供應鏈風險。
整體而言,這類風險的攻擊情境包括:易受攻擊的Python函式庫、直接篡改、模型遭微調、預訓練模型風險、第三方供應商遭攻擊、供應鏈滲透、雲端攻擊、LeftOvers 攻擊、WizardLM 假冒攻擊、逆向工程App、資料集投毒、條款與隱私政策等變更。
風險4 資料與模型投毒(Data and Model Poisoning)
意指攻擊者利用操弄的資料去影響LLM訓練過程,包括從預訓練(Pre-training)影響模型的基礎學習資料,從微調(Fine-tuning)影響特定應用場景的模型行為,以及從另一階段嵌入(Embedding),去影響模型如何將文字內容轉換為機器可理解的數值向量,進而造成風險,包括模型安全性下降、影響模型決策準確度,甚至產生有偏見或有害內容,以及被惡意利用來影響其他系統,甚至植入漏洞、後門或偏見。
此外,開源平臺或共享模型庫中的LLM更要提防,需要當心載入模型時就執行惡意程式碼,甚至是在滿足特定的條件下,才會觸發的潛伏代理(Sleeper Agent)」式攻擊。
風險5 不當輸出處理(Improper Output Handling)
LLM生成的內容在傳遞給其他系統或元件之前,恐因缺乏適當的驗證、過濾與處理,而產生的資安風險。由於LLM的輸出可被提示詞影響,這類風險類似於讓使用者間接控制系統的額外功能。
若攻擊者若利用這項弱點,可能導致前端攻擊(如XSS、CSRF)與後端攻擊(SSRF、權限提升、RCE)。
基本上,輸出處理不當主要關注點是,LLM產生的輸出是否經過適當的驗證。而在十大LLM風險中,還有另一項容易與此狀況混淆的是過度代理授權,這種風險則是著重於LLM是否被賦予過高的行動權限。
風險6 過度代理授權(Excessive Agency)
LLM在應用程式中被賦予過多行動能力,能透過外掛、工具或擴充功能執行操作,若沒有節制或積極控管適用範圍,可能會造成資安問題。一旦LLM產生意外、模糊或遭操控的輸出,可能導致應用程式執行有害行為。
為何LLM會面臨過度代理問題?原因包括:功能過多(允許LLM控制過多操作)、權限過大(LLM獲得超過應有的系統存取權限)、自主性過高(LLM可在無監管下自行決策)。
若LLM具備與其他系統互動的能力,過度自主性可能導致存取或洩露機密資訊、修改關鍵決策或執行未授權操作,甚至過度調用資源影響可用性。
風險7 系統提示詞洩露(System Prompt Leakage)
原本設計為根據應用程式需求引導模型輸出的系統提示詞(指系統給模型的指示,非使用者給模型的指示),但可能因為不慎洩露重要機敏資訊,使攻擊者可利用內部機制、規則與權限的資訊,成為發動攻擊的切入點。
例如,系統提示詞可能揭露應用程式的敏感功能或資訊,或是暴露內部規則、篩選條件、權限與角色結構,攻擊者可利用這些資料進行未經授權的存取,或是了解系統運作並尋找弱點或繞過安全控制。還要注意的是,即便系統提示詞未直接外洩,攻擊者仍可藉由分析輸出結果,推測模型的安全機制與限制。
風險8 向量與嵌入弱點(Vector and Embedding Weaknesses)
此類弱點會危害使用檢索增強生成(RAG)技術的LLM系統,問題源於向量與嵌入的生成、儲存,或檢索方式,可能被無意或有意的攻擊者利用,注入有害內容、操控模型輸出,甚至存取敏感資訊。
基本上,RAG是一種模型調整技術,結合預訓練語言模型和外部知識來源,幫助提高回應效能與精準度,避免LLM因訓練資料的限制,而產生幻覺(Hallucination)問題。在這過程中,系統透過向量機制與嵌入技術查找,並且整合外部知識,然而,一旦RAG索引方式設計不當或遭攻擊者動手腳,就會產生上述安全風險。
風險9 錯誤資訊(Misinformation)
由於LLM產生錯誤資訊,對依賴模型的應用程式構成風險。當LLM生成看似可信但錯誤或誤導資訊,可能導致資安問題、商譽受損,以及法律風險。
事實上,幻覺(Hallucination)是LLM錯誤資訊產生的主因,由於LLM依賴統計模式來填補訓練資料的空缺,並非真正理解語言的含意,只是模仿人類的語言模式,所以會有這樣的現象,給出偏離事實的錯誤資訊,或是給出看似合理但實際並無根據的論點。
使用者行為也將加劇這風險的影響。一旦使用者過於依賴LLM,未經驗證就採信,這種過度信任的問題,加劇錯誤資訊的影響。
風險10 無限資源耗盡(Unbounded Consumption)
當LLM在處理用戶輸入時,允許無限制且未受控的運算,可能導致系統資源被過度使用或濫用,引發一系列安全風險。因此需要LLM應用開發者因應,建立資源限制與避免濫用的防範措施。
具體而言,這類耗用層面的風險可細分4種,包括:(1)惡意用戶發動阻斷服務攻擊(DoS),導致系統崩潰或性能嚴重下降;(2)雲端環境若不對此進行限用,可能導致高昂成本;(3)攻擊者透過大量查詢來重建模型,非法複製該模型的能力;(4)過度請求,可能導致系統回應速度變慢或影響業務運行。
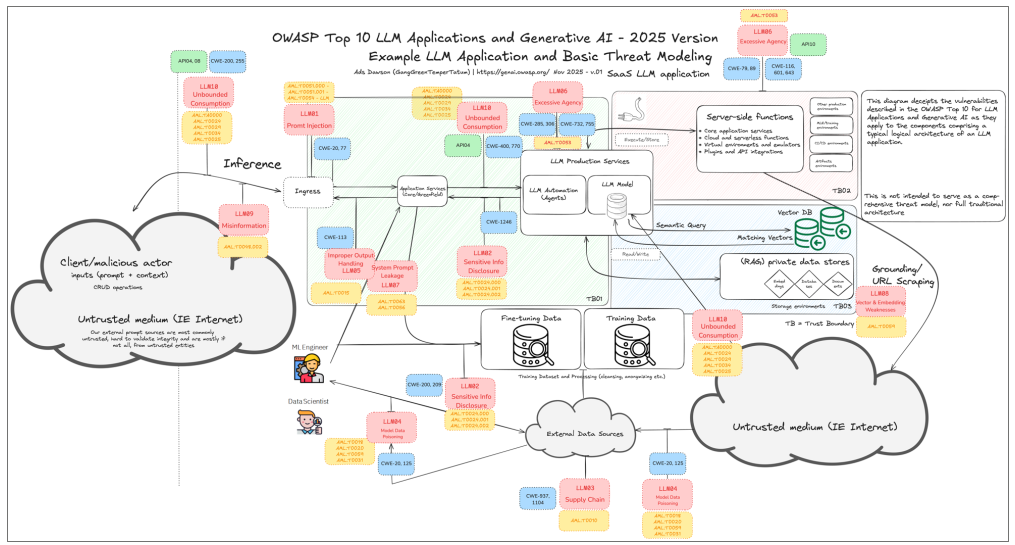
對於LLM應用程式的資安風險,OWASP提出一整套典型的架構範例並結合基本威脅模型,描繪LLM可能存在的各種攻擊面與安全風險,呼應OWASP Top 10所強調的風險類別,並透過視覺化呈現方式,幫助開發者和安全專業人員理解這些潛在威脅。(圖片來源/OWASP)
藉助網路社群資源來認識LLM風險
想要掌握LLM資安風險,網路上有許多社群認可的資源可以運用,例如,OWASP 是一個全球性的非營利組織,以發布「OWASP Top 10」風險排名而聞名,像是「十大網站安全風險」與「十大行動應用程式安全風險」。隨著LLM的興起,OWASP 近年也針對其風險進行分析與排名。
2024年11月,OWASP公布「十大LLM應用程式安全風險」2025年版。另於2025年3月發布多國語言版本的文件,涵蓋西班牙文、德文、簡體中文、正體中文、葡萄牙文、俄文。
OWASP亦提供線上學習資源,透過影片介紹LLM十大風險(連結)。
臺灣目前也有這方面的內容介紹資源,例如:由臺灣IT社群知名的專家、多奇數位創意公司技術總監黃保翕(保哥)製作的中文導讀介紹影片。(連結)
OWASP以外的AI資安風險參考資源:
● MLCommons,開放工程聯盟:LLM安全性測試工具AILuminate
● ISO,國際標準組織:ISO 42001「AI管理系統標準(AIMS)」
● NIST,美國國家標準與技術研究院:AI風險管理框架(AI RMF)
●MITRE,美國非營利資安組織:對抗AI系統威脅版圖(ATLAS)防禦知識庫
想要知道更多關於LLM(大型語言模型)的資訊嗎?
趕快點擊以下連結喔!!
 線
線