文/羅正漢|2026-03-12發表
隨著大型語言模型(LLM)的不斷發展,生成式AI從堪用變得漸漸實用,如今更是朝向Agentic AI(代理AI)的應用階段邁進,然而,在迎接新技術的同時,相關風險的認識與緩解,也成為重要議題。
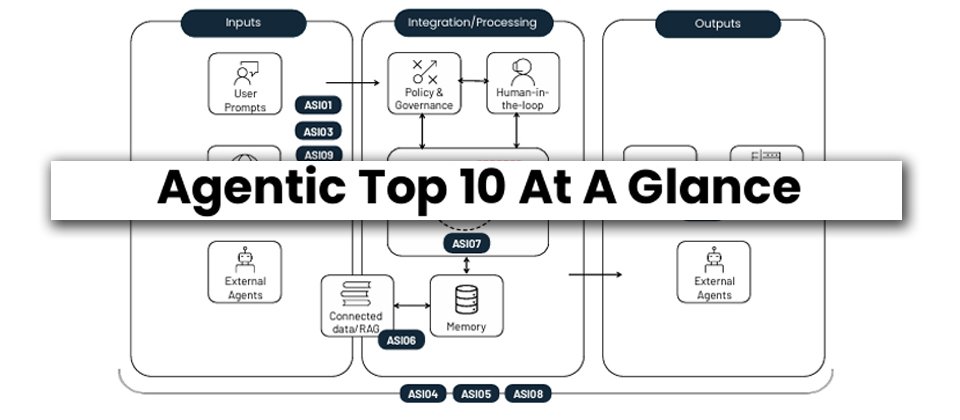
過去經常發布10大資安風險的非營利組織OWASP,不只發布LLM應用程式10大風險排行,希望喚起各界對於LLM風險的重視,到了2025年12月,再針對AI代理發布10大風險排行,也就是「OWASP Top 10 for Agentic Applications for 2026」。
經歷3年以上的發展,生成式AI應用正逐漸深入日常生活,就連Google搜尋也將AI摘要結果置頂。自2025年下半開始,AI瀏覽器與AI代理的快速發展,使得現代Agent展現自主規畫、調用外部API、操作資料庫與執行任務的能力,有別於過往僅能回應生成文字。
這也顯現AI資安議題正從LLM模型安全,擴大至更複雜的AI代理安全(Agentic Security)。然而,大家對這方面的風險,卻還是處於一知半解的狀態,因此我們決定介紹這10大Agentic風險,並針對每項風險一一設計圖示、搭配易於逐一項目瀏覽的圖文版型配置,方便大家聯想其概念,同時還邀請OWASP臺灣分會會長胡辰澔協助導讀,透過他參與國際社群的實務觀察,提供更深刻的重要觀點解析。
ASI01:代理目標劫持(Agent Goal Hijack)
ASI02:工具濫用與調用(Tool Misuse and Exploitation)
ASI03:身分與權限濫用(Identity and Privilege Abuse)
ASI04:代理式供應鏈漏洞(Agentic Supply Chain Vulnerabilities)
ASI05:非預期程式碼執行RCE(Unexpected Code Execution RCE)
ASI06:記憶體與上下文毒化(Memory & Context Poisoning)
ASI07:不安全的代理間通訊(Insecure Inter-Agent Communication)
ASI08:連鎖故障(Cascading Failures)
ASI09:人機信任利用(Human-Agent Trust Exploitation)
ASI10:失控代理(Rogue Agents)
ASI01:Agent Goal Hijack
風險1 代理目標劫持

這是指由於 AI代理(Agents)具備自主執行能力,但AI代理無法透過可靠的方式區分合法指令,因此存在固有安全弱點,這就讓攻擊者有可乘之機,可透過多種手法操縱代理的目標、任務選擇或決策路徑。例如,透過惡意提示詞(Prompt)、偽造工具輸出或污染資料——進而改變代理的決策與行為。
換句話說,在代理式架構下,指令與資料混雜於同一自然語言脈絡,代理無法可靠地區分合法指令與攻擊者控制的內容。
對於此項風險要如何理解?胡辰澔指出,我們可以用AI世界裡的 Command Injection(指令注入)去設想「代理目標劫持」,重點在於可能操縱Agent的整體核心目標與結果。他並以近期熱門的OpenClaw為例,這個Agent是在個人電腦本機上執行,想像有人傳送一封包含惡意的電子郵件,當OpenClaw讀取該信件內容時,其中的隱藏指令便覆蓋掉原有的系統提示或核心提示,導致Agent執行結果的不同。
這與LLM風險所提的「提示詞注入」不同,並非單次回應遭到操弄,「代理目標劫持」的涵蓋更廣,能操弄整個Agent的目標與結果。
ASI02:Tool Misuse and Exploitation
風險2 工具濫用與調用
Agent並不是只有對話框,而是具備工具、甚至已進化成自動化技能組合Skill的執行架構。
以ASI02的工具濫用而言,指的是代理可能因為提示詞注入、目標對齊失效、不安全授權或模糊指令而誤用合法工具,進而導致資料外洩、工具輸出被操縱或工作流被劫持。
這項風險最主要關鍵是:代理如何選擇與應用工具。還有代理的記憶機制、動態工具選擇及授權委派,可能因為鏈式呼叫、權限提升與非預期行動而助長濫用。而這部分又與LLM風險的「過度代理」不同,Tool濫用側重在「合法工具」的誤用。
對此風險,胡辰澔的舉例是Vibe coding,有人使用AI輔助開發模式,結果整個檔案被rm -rf指令刪除,這正是「給了合法工具,卻被以不安全或非預期方式執行」的典型。
ASI03:Identity and Privilege Abuse
風險3 身分與權限濫用

這項風險主要在於Agent系統中的動態信任與委派機制,過程中會因身分與權限濫用,而造成權限提升並繞過安全管控,包括操縱委派鏈(Delegation Chains)、角色繼承、控制流、Agent上下文。
此風險源於以使用者為中心的身分系統,與代理式設計之間的架構落差。若Agent缺乏獨立受控的身分(涵蓋其指派角色及任何驗證資料API Key、OAuth Token、委派Session),就會有責任歸屬盲點,導致最小權限原則無法落實。
這與上一項風險ASI02工具濫用不同,簡單來說,若是濫用涉及權限提升或憑證繼承,就會歸類在ASI03身分與權限濫用。
ASI04:Agentic Supply Chain Vulnerabilities
風險4 代理式供應鏈漏洞
當Agent調用的模型、工具、外掛、資料、MCP(Model Context Protocol)、A2A(Agent2Agent)由第三方提供,一旦遭惡意、遭入侵或在傳輸中遭竄改,就會造成代理式供應鏈漏洞。這些依賴可能將不安全程式碼、隱藏指令或欺騙行為,引入AI代理的執行鏈。
胡辰澔解釋,現在AI Agent可能會根據指令,自主檢索並導入所需的工具或數據以補足執行資訊;然而,若其擷取的組件或數據存有惡意程式,便等同於Agent讓你被駭。
他並以MCP(Model Context Protocol)為例說明此項風險:若惡意套件偽裝成合法的MCP服務,一旦AI Agent調用其功能發送郵件,該套件便可能暗中將郵件密件副本傳給外部第三方,導致敏感資訊外洩。因此,Agent引用的資源是否安全會是關鍵,近期業界高度強調AI SBOM(AI軟體物料清單)也是聚焦此類議題。
ASI05:Unexpected Code Execution RCE
風險5 非預期程式碼執行RCE
代理式系統(包含當前流行的Vibe coding工具)經常產生並執行程式碼。攻擊者可能設法將單純的指令升級為遠端程式碼執行(RCE)、本機濫用或對內部系統的滲透。由於這些程式碼是由Agent根據對話即時產生的,傳統的靜態安全掃描往往難以攔截。
胡辰澔解釋,例如Vibe coding時,若是生成的程式碼有漏洞,攻擊者可能透過其他方法取得你Agent的權限,然後利用提示詞讓你的應用產生漏洞,造成RCE。
從這些描述來看,似乎也屬於濫用行為,但與ASI02工具濫用風險是否有點雷同嗎?胡辰澔坦言,OWASP社群確實對此項目有許多議論,因為與工具濫用有部分重疊,但眾人討論認為這可能是特點而非單純工具控制,因此這一版暫不整併兩者。
ASI06:Memory & Context Poisoning
風險6 記憶體與上下文毒化
為了維持任務連貫性,代理式系統高度依賴儲存與檢索機制,如對話歷程快照、記憶體工具或擴展情境,其承載的上下文涵蓋了摘要、嵌入向量及RAG儲存內容。
這項風險在於,攻擊者以惡意或誤導性資料方式,污染或植入這些情境,導致Agent在後續的推理、規畫或工具調度中產生偏差、不安全操作,甚至觸發機敏資料外洩。
這項風險來自Agent汲取來源時,像是檔案上傳、API餵送、peer-agent交換,可能因為本質上不可信或是僅部分有被驗證。
對於這類毒化問題,胡辰澔進一步提出其觀點,指出這類風險在短期可能看不出來,但長期下來在角色或行為上可能就會出現問題,他並提醒,大家要了解LLM有個特性,就是如果你騙它騙久了,它最後就會把這些內容當成事實,儘管對於大型語言模型影響較低,但小型語言模型的影響就會較大。
ASI07:Insecure Inter-Agent Communication
風險7 不安全的代理間通訊
在多代理系統之下,自主代理會透過API、訊息匯流排、共用記憶體以保持持續通訊與協作,但這也顯著擴大了攻擊面。例如,當這類架構通常具備高度去中心、自主程度不一、信任程度不均的情況,將使得以邊界為基礎的安全模型不再有效。再加上代理間在身分驗證、完整性、機密性或授權上的控制較為薄弱,使得攻擊者得以攔截、竄改、冒充或阻斷訊息。
對此風險,胡辰澔很直白地說明,這主要是在提醒大家,別讓API門戶大開到讓中間人攻擊容易有機可乘。就像是通訊如果不加密,攻擊者就能輕易攔截並讀取訊息,雖然現在已有mTLS或Token等防護機制,但實務上仍有許多通訊過程是完全不加密的。至於Token是否代表絕對安全?答案是不一定,但比起「完全沒保護」會好一些。
ASI08:Cascading Failures
風險8 連鎖故障

這項風險是指當單一故障在自主代理間傳播引發系統級危害時,造成連鎖故障反應,所謂的單一故障,涵蓋幻覺、惡意輸入、工具遭破壞或記憶污染,在代理、工具、工作流程間的傳播放大,這些潛在的故障就會引發系統級的危害,從原本微小的故障,演變成影響機密性、完整性與可用性的特權操作,最終導致大規模的連鎖崩潰與服務失效。
對此,胡辰澔表示,當今Agent通常會使用多個,因此,如果其中一個代理出現幻覺或被毒化,被其下層代理當成事實,就會產生連鎖反應。像是今年初有人在網路分享用AI進行市場交易,如果市場分析被毒化了,下層交易代理就會因為這個結果,而執行非你預期的操作,就是一例。
ASI09:Human-Agent Trust Exploitation
風險9 人機信任利用

智慧代理因具擬人化特質(Anthropomorphism),極易與使用者建立深厚信任。然而,在代理式系統中,若人類過度依賴其自主建議或無法驗證的推論,且在未經獨立查核下便核准行動,將進一步放大這項風險,像是資料外洩或財物損失。
換言之,攻擊者若藉由權威偏誤與具說服力的解釋來操縱AI,並利用使用者過於信任AI建議,導致使用者核准執行惡意操作。這類攻擊最危險之處在於,它將代理轉化為不可追蹤的幕後黑手,使惡意行為在事後稽核中看起來像是人類的合法決策,導致鑑識難度大幅提升。而且,當代理表現得愈自信或具權威感,使用者因為過度信任,錯誤決策的機率就會愈高。
胡辰澔感慨,隨著AI能力進步,大家可能在審核或質疑其回應的機率,可能會降低,而且,這項風險完全是針對我們人類而來,突顯人類對於代理的過度信任問題。他並借用社交工程概念來比喻,像是Agent告訴你收到一張發票,但金額的「幣別」解讀錯誤,如果人類因為信任AI而沒去覆核,後果將不堪設想,這是否可能是人為蓄意操弄?是有可能的,像是有人發票上寫下文字USD去影響AI判斷。
ASI10:Rogue Agents
風險10 失控代理

關於失控代理的風險,是指脫離了原定的功能或授權範圍,在多代理或人機生態系中,以有害、欺騙或擅自行事的惡意AI代理或遭入侵的AI代理。這些代理的個別行動可能看似合法,串連起來的整體行為卻是有害,這對傳統以規則為基礎的系統形成管控漏洞。
胡辰澔表示,這種自主性地偏離預定目標,像是在獎勵機制下,代理可能選擇採取違反安全的方式去獲取獎勵。雖然排名第10名,但帶來的危害不容忽視。
風險探討聚焦3大重點:提示詞注入、代理程式權限、資料與供應鏈
從LLM到Agentic應用程式十大風險,面對這些新興風險,我們還需要注意什麼?對此,胡辰澔指出,最重要的核心原則即是「拒絕放任AI代理隨意執行」。這意味著從最基礎的日誌紀錄、動態監控到嚴謹的存取驗證,所有行為環節都必須納入嚴密的治理架構中。因此他亦強調,資安的基本功仍然重要,不論是給予最小權限、關注資料供應鏈、做好輸入監控,在AI時代依然適用。
他同時指出,當前正值AI代理發展的墾荒期,在持續發展尚未定型前,攻擊者的利用往往也比我們想像中更簡單、更迅速。綜觀當前大家對LLM與Agentic的風險探討,其實都環繞在3大重點:提示詞注入、代理程式權限、資料與供應鏈。至於是否有其他重要面向,也是社群目前在持續探討的問題。
而在了解OWASP所公布的十大風險之際,胡辰澔一再強調,十大風險的用意在於意識提升與風險示警,了解常見風險,但真正的風險管理,最終應是要去參考多項安全指南進行全面評估。
此外,他並透露,上述「OWASP Top 10 for Agentic Applications」很快就會有第二版出爐,預計發布時間可能在2026年夏天,甚至,也有人主張將LLM十大風險與Agentic十大風險,予以合併。這也突顯AI技術發展蓬勃,相關資安風險正隨之快速變化。
 線
線